

In his book, “Weaving the Web”, Sir Tim Berners-Lee shared his vision about the future of his creation: “In an extreme view, the world can be seen as only connections, nothing else. We think of a dictionary as the repository of meaning, but it defines words only in terms of other words. I liked the idea that a piece of information is really defined only by what it’s related to, and how it’s related. There really is little else to meaning. The structure is everything.”
This idea of taking the web (which is, if nothing else than a gigantic network of interlinked web pages and resources) into its next step in evolution, a “Semantic Web”, has been a guiding large effort in research and development since its inception its 2001. In a nutshell, the Semantic Web is an extension of the WWW where not only web pages have addresses (e.g. the website for MeMAD is located at “http://memad.eu”) but any resource, whether it is an entity (person, location, organization..), an event (elections, wars, movements, ..), a medium (movie, painting, book ..), or concepts (global warming, immigration, society..), should have an accessible Web address. Then these resources should be connected via explicit semantic relations. For Example: Tim Berners-Lee {invented} The World Wide Web. The definition of the vocabulary used to define such resources and the relations among them is called an Ontology. There are many available ontologies on the web today, ranging from open-domain ones such as Schema.org and DBPedia Ontology to close-domain ones such as MusicBrainz for music, Geonames for geographical data etc. Because everything has a URI, we can express the fact that Tim Berners-Lee is the author of the “weaving the web” as:

or as we call the “triple”:
(http://dbpedia.org/resource/Tim_Berners-Lee, http://dbpedia.org/ontology/author, http://dbpedia.org/resource/Weaving_the_Web)
This triple, once hosted somewhere on the web, becomes part of the “Semantic Web”, a web-based, machine readable record of facts and knowledge about the world.
There is much fun to be had working on ontologies, but for the purposes of our project, we want to model the large amount of data about audiovisual media into one cohesive database that provides a unifying layer of abstraction over the natural variety that comes with data coming from different sources and content providers in the project. This layer of abstraction and data representation is called a Knowledge Graph, a term first popularized when Google announced the new adoption of Semantic Web-like representation of facts about different subjects and topics of search results such as people, books, media, and historical events.
The MeMAD Knowledge Graph comprehends all the metadata we have on the MeMAD corpus we’re working with. This includes multiple connected resources such as program content description (title, keywords, duration, genre ..), information about broadcasting (broadcasting date and time, channel ..), participating agents and their roles, technical media metadata etc.
The problem with the metadata we have is that, since it comes from different sources and different departments, it presents a challenge in querying and usability. Each archiving department adopt a homegrown format for documenting and describing the broadcasted content. That’s why we use the European Broadcast Union EBUCore ontology (also known as Tech 3293), which provides a “framework for descriptive and technical metadata and audiovisual ontologies for semantic web and linked data developments”. EBUCore provides the vocabulary we use to represent the content of our Knowledge Graph in a standard and thought-through manner.
By the end of the integration, the data goes from looking like this:
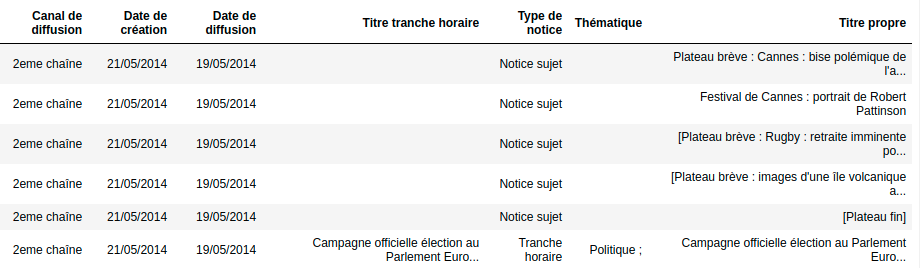
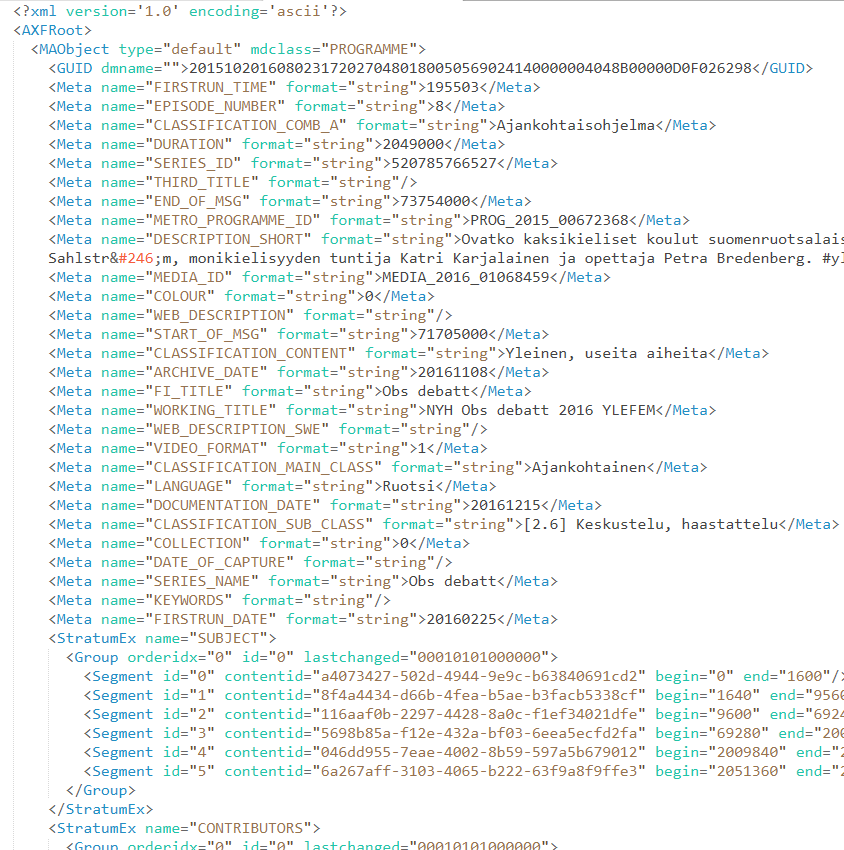
To something like this:
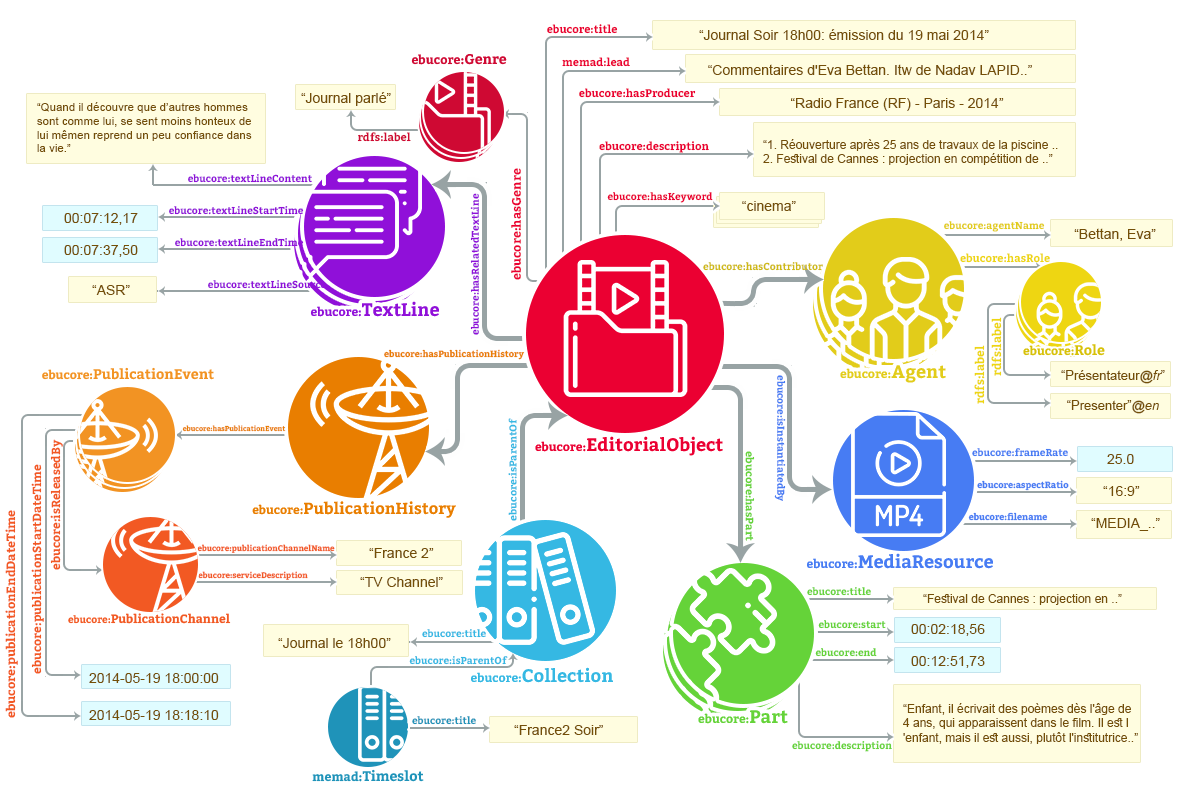
The MeMAD knowledge graph visualization.
This example can be viewed at: http://data.memad.eu/yle/stromso/d3c864a1c28cf83839c3e4f45405113f31079361
Since every element in the knowledge graph is identifiable with a URI, it can be accessed through a web interface, and interlinked with other elements that share some of its characteristics. This makes accessing and querying the heterogeneous data much easier and allows to build applications on top of the Knowledge Graph regardless of the original format and provenance of the data.