

Imagine that someone has recorded a series of hundreds of meetings and your task is to find out who spoke where and when. Sounds like a lot of transcription work, especially if the speaker turns are short, spontaneous and overlapping and sometimes hard to understand even after careful listening.
The automatic approach to this task is known as speaker diarization. The goal is to produce a diary of all speaker appearances. The current state-of-the-art solutions study thousands of speakers, for example, from Youtube videos to construct a set of features that optimally separates the speakers by their voices. These spoken fingerprints do not directly correspond to any audible patterns in the time-frequency space, but are latent representations learned by a deep neural network that was trained to robustly identify the speakers. These effective multi-dimensional representations are known as speaker embeddings. Once extracted, the speaker embedding can be used not only to train models that recognize speakers, but also to detect speaker turns and change points. Additionally, this representation is useful for taking the speakers into account in attention-based end-to-end speech recognition and synthesis, that is, when transforming speech to text and text to natural speech.
In MeMAD the speaker diarization is an important part of the production of automatic descriptions for audiovisual data. Detecting who spoke when is not only important for searching large video archives like YLE or INA, but also for quickly browsing through the discovered contents utilizing the discovered speaker turn structure. Another way to utilize speaker diarization reported in MeMAD has been to recognize and measure the speaking time per gender in public media (11).
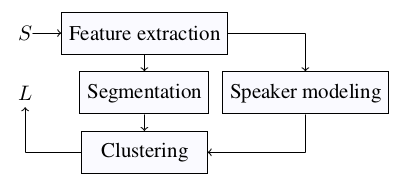
Diagram of processing steps for speaker diarization
A new method for speaker diarization called SphereDiar was developed at Aalto University by Tuomas Kaseva in his Masters’ thesis 2019 (1). The diagram (above) shows the integrated processing steps from input (S) which is speech split into overlapping 2 second windows to the output (L) which is the sequence of speaker labels for each window. The first block computes various spectral features that are known to characterize speech sounds. Then the segmentation step uses a deep neural network to suggest whether there is a single recognizable speaker or multiple speakers. The speaker modeling is another deep neural network that projects the feature vectors to a general speaker embedding space that was trained based on 6000 speakers extracted from the Librispeech and Voxceleb2 datasets (4, 5). The final step is a novel speaker clustering method which detects the most likely speaker label for each embedding. This as well as the other steps are described in detail in the IEEE ASRU paper (2). One interesting observation in the work was that the segmentation block is actually unnecessary. This is because the speaker modeling turned out to be powerful enough to extract the main speaker even in the presence of other speakers.
IEEE ASRU 2019 workshop and other publications

Tuomas Kaseva presenting the work at IEEE ASRU workshop December 2019
The method and its evaluation on over 200 AMI and ICSI meetings (6, 7) were presented in the article (2) published in proceedings of IEEE Automatic speech recognition and understanding (ASRU) workshop in December 2019 (9). The method was also evaluated in Voxceleb speaker recognition challenge 2019 (8). It performed very well (ranking 11/52) despite being fairly light and simple compared to many other state-of-the-art methods. Furthermore, we studied the utilization of speaker embeddings in speaker-aware speech recognition in the article (3) published in proceedings of IEEE ICASSP 2020 that will appear in May 2020 (10).
References and further information
- Tuomas Kaseva. MSc thesis: SphereDiar — an efficient speaker diarization system for meeting data. Master’s thesis, Aalto University, 2019. The SphereDiar code: https://github.com/Livefull/SphereDiar
- Tuomas Kaseva, Aku Rouhe, and Mikko Kurimo. Spherediar – an efficient speaker diarization system for meeting data. IEEE ASRU 2019.
- Aku Rouhe, Tuomas Kaseva, and Mikko Kurimo. Speaker-aware training of attention-based end-to-end speech recognition using neural speaker embeddings.. IEEE ICASSP 2020.
- Panayotov, G. Chen, D. Povey, and S. Khudanpur. Librispeech: an ASR corpus based on public domain audio books. IEEE ICASSP 2015.
- S. Chung, A. Nagrani, and A. Zisserman. Voxceleb2: Deep speaker recognition. Interspeech 2018.
- McCowan, J. Carletta, W. Kraaij, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V. Karaisko. The AMI meeting corpus. International Conference on Methods and Techniques in Behavioral Research, 2005.
- Janin, D. Baron, J. Edwards, D. Ellis, D. Gelbart, N. Morgan, B. Peskin, T. Pfau, E. Shriberg, A. Stolcke. The ICSI meeting corpus. IEEE ICASSP 2003.
- The home page of VoxSRC – Voxceleb speaker recognition challenge 2019: http://www.robots.ox.ac.uk/∼vgg/data/voxceleb/competition.html.
- The home page of ASRU 2019: http://asru2019.org/wp/
- The home page of ICASSP 2020:https://2020.ieeeicassp.org/
- Analysing 1 million hours French TV radio for describing gender equality. MeMAD blog, October 2019: https://memad.eu/2019/10/01/analysing-1-million-hours-french-tv-radio-describing-gender-equality/