

Typical machine translation is done on the sentence level. This means that sentences are translated in isolation without considering the flow in the surrounding context. From a human perspective, this is less than satisfactory. A natural text needs to be well connected, and the story it tells should be coherent and fluent. Any human translator will use plenty of connectives and referential structures to improve the readability of a translation in the same way as creating original text.
He saw children playing with binoculars.
Document-level (or “discourse-aware”) machine translation has already been studied for some years, albeit without real progress. Researchers like Christian Hardmeier and Sharid Loaiciga looked at various discourse phenomena and how they influence translation.
Current Incentives for Research
A dedicated series of workshops on the topic (DiscoMT) has been started, and continues to run with a new iteration this year. In early years, the focus was set on referential pronouns as one of the most explicit phenomena that can be observed on the discourse level. The tricky part is that such pronouns need to agree with their antecedents—the items they refer to. Why is that a problem? Well, for example, if there is gender marking in one of the languages that is different from that of the other language, then there would be a problem when translating a pronoun in isolation without looking back to the item it refers to. Let’s look at the following examples:
| Input | The funeral of the Queen Mother will take place on Friday. It will be broadcast live. |
| (a) | Les funérailles de la reine-mère auront lieu vendredi. Elles seront retransmises en direct. |
| (b) | L’enterrement de la reine-mère aura lieu vendredi. Il sera retransmis en direct. |
| Input | Der Strafgerichtshof in Truro erfuhr, dass er seine Stieftochter Stephanie Randle regelmässig fesselte, als sie zwischen fünf und sieben Jahre als [recte: alt] war. |
| Reference translation | Truro Crown Court heard he regularly tied up his step-daughter Stephanie Randle, when she was aged between five and seven. |
| MT output | The Criminal Court in Truro was told it was his Stieftochter Stephanie Randle tied as they regularly between five and seven years. |
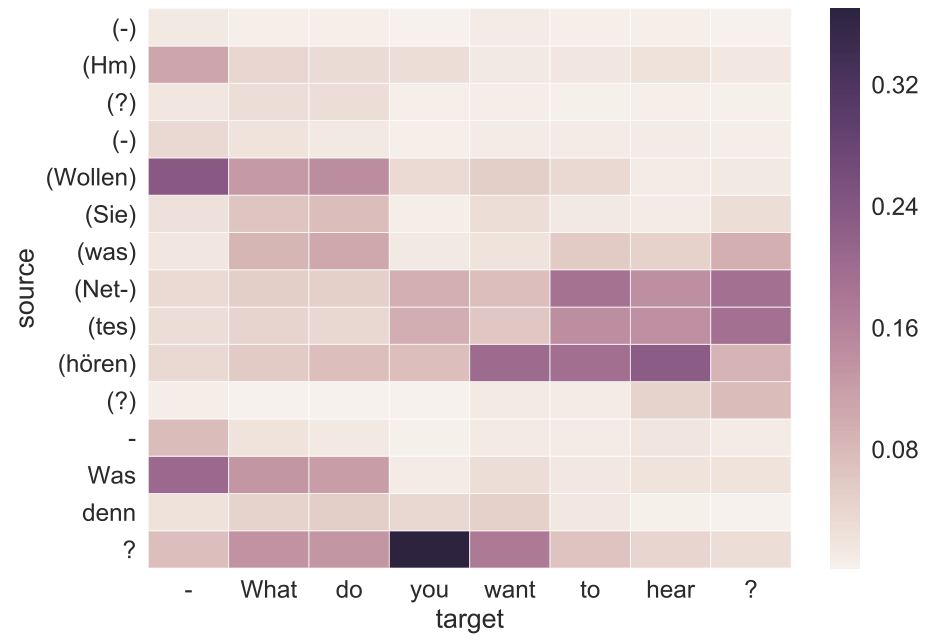
The interest in document-level models is just growing and various models have recently been proposed to extend the context considered in neural machine translation. A simple extension is to run a sliding window over the data and to connect at least a small number of subsequent sentences in translation. This can be done in the source, in the target, or in both. In Tiedemann & Scherrer (2017), we proposed such a strategy showing that connections can be learned between sentences and that modern attention-based NMT is capable of learning from extended context.
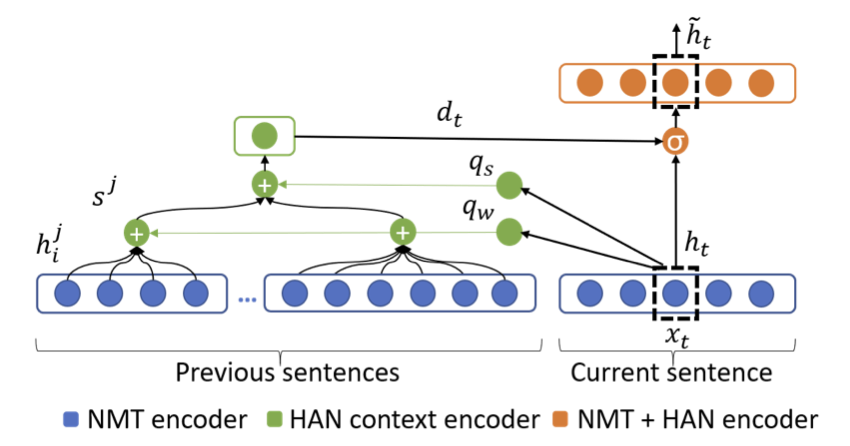
Simple concatenation has its limits and other approaches propose some kind of knowledge aggregation that can be passed to the single-sentence translation engine. Hierarchical and selective attention mechanisms are used to aggregate relevant information for the translation of coherent text.
This year, WMT featured a task on document-level machine translation. Teams were encouraged to work on document-level models, and promised a dedicated evaluation to decide whether such models have led to improved coherence and translation quality. We have participated in that task as well for short news documents translated from English to German. We tested concatenation models and hierarchical attention models, and evaluated the results with a shuffled and a natural test set. The shuffled version randomly shuffles sentences, which should confuse the document-level model. Below, we show the results of our concatenation models (in BLEU scores) on both versions of the same news data test set:
| System | Shuffled | Coherent |
| Sentence-level MT | 38.96 | 38.96 |
| Concatenate 2 source sentences | 36.62 | 37.17 |
| Concatenate 3 source sentences | 34.14 | 34.39 |
| 2 source + 2 target sentences | 38.53 | 39.08 |
The first line represents the baseline without any document-level information (translation of single sentences). The second and third models extend the context on the input side (source). The last model translates blocks of 2 input sentences (source) into 2 output sentences (target). This is done in a sliding-window fashion, and we evaluate only the second sentence in each block (with a special treatment of the first sentence of a document).
What can we learn from this?
The positive side of the experiment is that all document-level models seem to pick up valuable information, which shows in the improved scores on coherent test sets. However, none of the document-level models is very successful compared to the single-sentence model. The only (but insignificant) improvement was achieved with the 2+2 model. This is certainly disappointing, and a trend that we have seen in most of the work on document-level machine translation. Here, we also omit the results from hierarchical attention models, as they are even worse in comparison.
First of all, document-level machine translation is difficult, and requires further attention. Secondly, standard evaluation is not appropriate, and this has already been pointed out in much of the background literature. It will be interesting to see the outcome of the manual evaluation at WMT in August as well as the new developments that will be presented at DiscoMT and related events in the future.
References
Christian Hardmeier: Discourse in Statistical Machine Translation. PhD Thesis, Uppsala University.
Sameen Maruf, Andre F. T. Martins, and Gholamreza Haffari: Selective Attention for Context-aware Neural Machine Translation. NAACL-HLT 2019.
Lesly Miculicich, Dhananjay Ram, Nikolaos Pappas, James Henderson: Document-Level Neural Machine Translation with Hierarchical Attention Networks.
Jörg Tiedemann and Yves Scherrer: Neural Machine Translation with Extended Context. DiscoMT 2017.