

What is audio tagging?
If you are a frequent social media user, then you must be familiar with the word ‘tag’. This type of tagging normally happens when you find a funny meme or video that perfectly depicts your friends or matches their need. This process contains analyzing the content and assigning it to relevant people, which somewhat resemble to classification. So what is audio tagging then? Instead of tagging people to particular content, audio tagging refers to the classification task involving the assignment of one or several labels, such as ‘dog bark’ or ‘acoustic guitar’, to a given audio signal.
Applications and role in MeMAD?
This classification task could bring many new possibilities for the AI (artificial intelligence) industries in applications involving the perception of sound, such as sound print, public surveillance, medical information monitoring, speech recognition, and music information retrieval. A good audio tagger can efficiently archiving thousands of sound files, thus helping build a sound effects library. For our MeMAD project, an audio tagger would be an auxiliary tool for multimedia content analysis. One of the most important goals in MeMAD is using machine to generate text descriptions for given media content. The results of speech recognition and images captions are surely sufficient enough for describing the content. But giving tags for non-speech segments can make better descriptions and giving context information for visual images. For instance, ‘distant dog barking’ in a video can not be recognized by images only. Two video demos we made are given in the two links below to illustrate how our audio tagger works. And the code for the tagger can be seen in https://github.com/ZhicunXu/AudioTagger.
Recognizing music content: https://www.youtube.com/watch?v=3ht2aEmn_lk
Recognizing general sound: https://www.youtube.com/watch?v=cvR3iA5and8
How do we build the tagger?
The wide variety of tags in the video demos are originated from the Google AudioSet ontology. This ontology has a hierarchical tree structure and covers more than 600 classes including human, animal, nature, music and miscellaneous sounds. Thus AudioSet is a suitable dataset for general purpose audio tagging.
In the recognition process, an audio signal is firstly transformed into log-mel spectrograms involving some fast Fourier transform and scaling of frequency bands. Then the spectrograms are split into non-overlapping segments with equal length. These segments can be seen as image data which can be fed into deep CNNs (convolutional neural networks) for training. The VGGish model AudioSet provided is a such CNN model that can generate 128 compact semantically meaning features for 1-second audio. Thus the audio signal is represented as a series 128-dimensional vectors. Finally, we applied multi-level attention models upon these vectors for training the model. An illustration can be seen below.
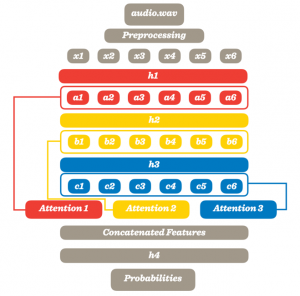 Each vector from x1-x6 has dimension of 128 representing a one-second audio. Hidden layers h1-h3 are used for generating different levels classifications results. The attention box assigns weights to each instance and gives out the weighted sum. These sums can be combined from any levels selected. The last hidden layer h4 is added for final classification. The output contains probabilities for all the sound classes. Simply speaking, different parts of an audio signal contribute to the final classification with different importance. Some parts might be more important, thus having larger weights. The final classification is a weighted sum for all the pieces.
Each vector from x1-x6 has dimension of 128 representing a one-second audio. Hidden layers h1-h3 are used for generating different levels classifications results. The attention box assigns weights to each instance and gives out the weighted sum. These sums can be combined from any levels selected. The last hidden layer h4 is added for final classification. The output contains probabilities for all the sound classes. Simply speaking, different parts of an audio signal contribute to the final classification with different importance. Some parts might be more important, thus having larger weights. The final classification is a weighted sum for all the pieces.
DCASE 2018 Task 2
We also participated the DCASE 2018 (Detection and Classification of Acoustic Scenes and Events) Task 2 which has different classes and training data. We fine-tuned the feature generation model AudioSet used and also used multi-level attention model for classification. Our system got one paper accepted by DCASE 2018 Workshop in November 2018, Surrey, UK. It achieved a MAP@3 score of 0.936 which outperformed the baseline 0.704. Even though we do not rank among the very best, we still provided an alternative system by fine-tuning an existing CNN model for feature generation. Our system also shows the possibility of adapting the solution to any other audio tagging tasks.
Our current version of tagger can generate several tags for each second audio or video based on selected context window. Tags with probabilities higher than selected threshold will be outputted. These probabilities can also be used directly as audio features along with image features when doing the video caption. However, there is still room for improvement, such as combining multi-scale features, training own CNNs instead of fine-tuning, and finding better ensemble techniques for models with different levels and number of segments.