

During the first year of our machine translation efforts in MeMAD, we focused on participating in two shared tasks on multimodal MT: the caption translation task at WMT 2018 and the speech translation task at IWSLT 2018. Starting with the good news, we can note that the MeMAD team won with a convincing victory over all participating teams at WMT 2018 for both, the English-to-German and the English-to-French translation task. The table below shows the top three English-to-German results with our submission at the top:
| Submission Name | BLEU | METEOR | TER | |
| 1 | MeMAD_1_FLICKR_DE_MeMAD-OpenNMT-mmod_U | 38.5 | 56.6 | 44.6 |
| 2 | CUNI_1_FLICKR_DE_NeuralMonkeyTextual_U | 32.5 | 52.3 | 50.8 |
| 3 | CUNI_1_FLICKR_DE_NeuralMonkeyImagination_U | 32.2 | 51.7 | 51.7 |
| Baseline | 27.6 | 47.4 | 55.2 |
English-to-French is similar and the following table shows the top three submissions and the baseline. In both cases, we beat the other teams by a wide margin.
| Submission Name | BLEU | METEOR | TER | |
| 1 | MeMAD_1_FLICKR_DE_MeMAD-OpenNMT-mmod_U | 44.1 | 64.3 | 36.9 |
| 2 | CUNI_1_FLICKR_DE_NeuralMonkeyTextual_U | 40.6 | 61.0 | 40.7 |
| 3 | CUNI_1_FLICKR_DE_NeuralMonkeyImagination_U | 40.4 | 60.7 | 40.7 |
| Baseline | 36.3 | 56.9 | 54.3 |
Translating image captions
The task at WMT is to translate image captions to another language with the aim to use additional visual information to help disambiguation. This means that text and image are given and a translation as text is expected:
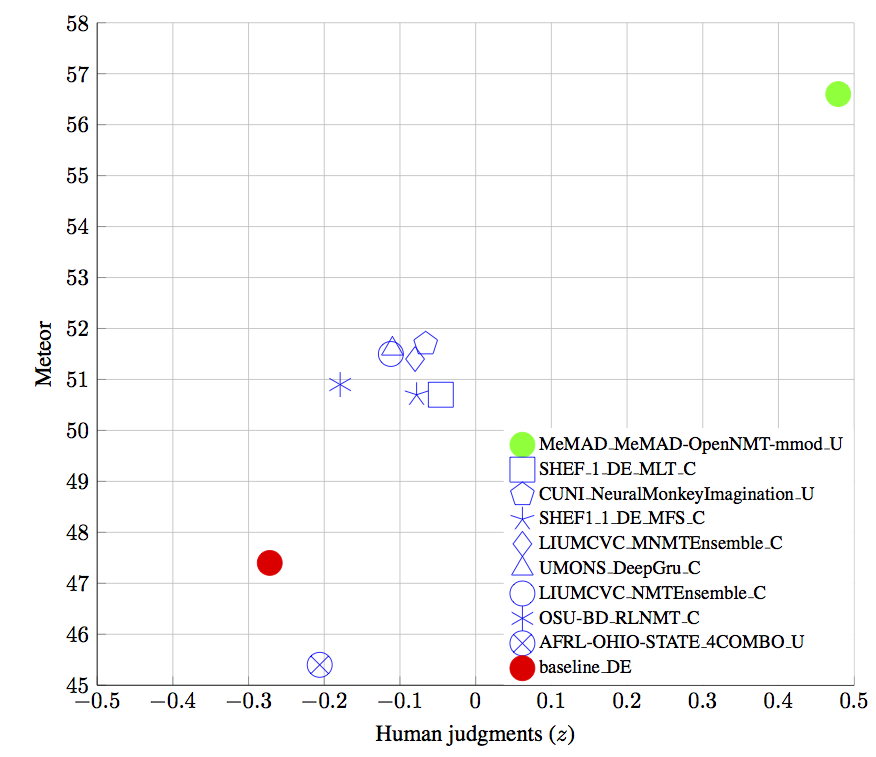
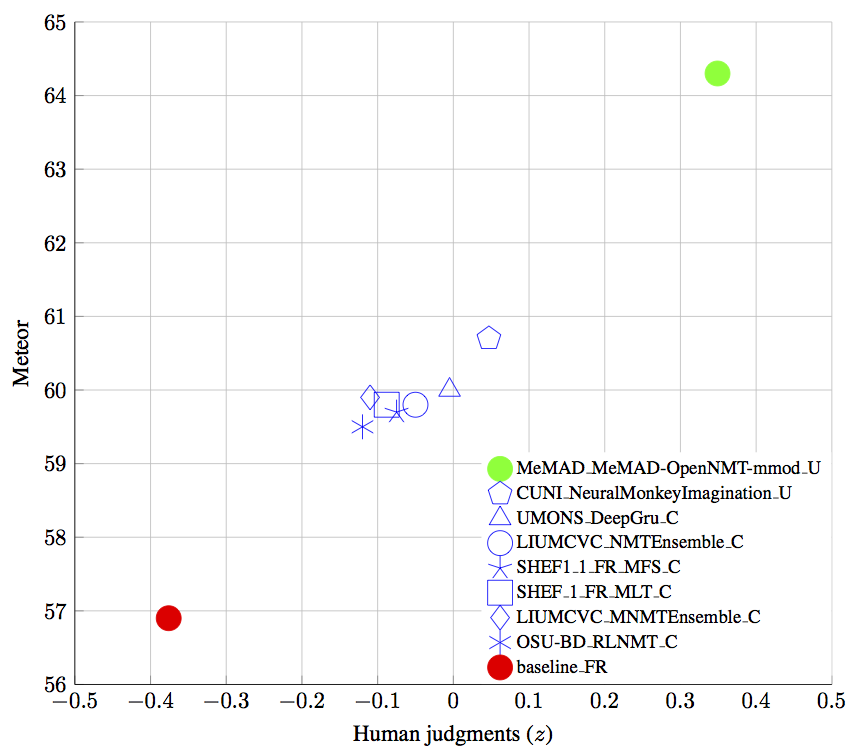
Before talking about the system that is behind our success let’s brag a bit more about the evaluation results from WMT. The manual evaluation revealed that our system was the only one that clearly outperformed the others coming close to the gold standard reference translation. The following plots come from the official publication on the findings from the shared task (the green dot is ours):
So, what did we do? (And this is the sad story…)
We started by a large variety of systems that we trained to determine the best use of textual data and visual features for the given task. In the final system, we adapted the Transformer architecture (Vaswani et al., 2017) to a multimodal setting by incorporating global image features based on Mask R-CNN (He et al., 2017) object localization outputs. For extracting the visual features, we used the Detectron software using ResNeXt-152 (Xie et al., 2017) as the basic image features. The final feature is an 80-dimensional vector expressing the image surface area covered by each of the MS-COCO classes, based on the Mask R-CNN masks. These visual features are then projected into a pseudo-word embedding which is concatenated to the word embeddings of the source sentence. In order to extend the training data we also created synthetic multimodal data by translating captions of the monolingual MS-COCO image dataset and added translated movie subtitles as additional text-only training data. Language-model based filtering further helped to reduce noise and to adapt the system to the target domain. This created a model that performed well on development data and, more importantly on the official test set as well.
Where did the visual features go?
But why would we say that this is the sad story? Naturally, we wanted to know what kind of image features that system is able to pick up and, therefore, we performed an experiment where we “blinded” the model during translation, meaning that we replaced the actual image features with a mean vector of those features in the training data. This is part of our ablation study and it revealed that the visual features are mostly without effect. The differences are small and mainly refer to changes in word order. No clear effects of successful disambiguation were found in the French data. The figure below shows even a negative example that becomes worse with visual features enabled.

The caption of this image was translated correctly as feminine “Eine Besitzerin steht still und ihr brauner Hund rennt auf sie zu.” when not using the image features, but as masculine “Ein Besitzer…” when using them. The original English text contains the word “her”. Does the model get confused by the person in the image with short hair wearing pants?
Ignoring the image is state of the art
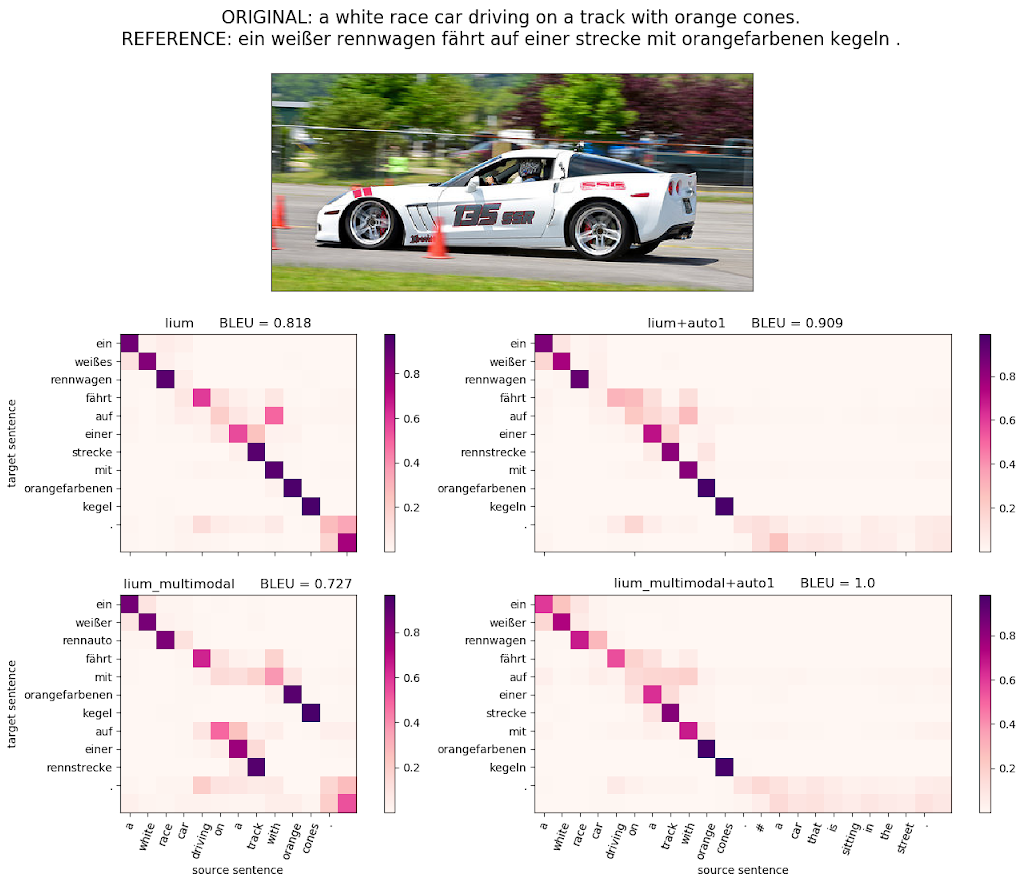
So, we were basically able to win the competition by creating a very successful text-based translation system, a fact that lead to a lot of discussions during the conference. Probably it will also lead to consequences in the setup of the multimodal task at WMT in the future. So far, most multimodal models are smart enough to ignore information that comes out of visual features. We have seen a similar effect when trying to combine the original English caption with automatically generated captions from the visual features. Below, we can see an example from the flickr data set where we include automatic captions in the translations on the right-hand side. Even though the BLEU scores might go up the system basically learns to ignore the automatic captions, which we can see in the attention patterns of the translation model. Well, this is fascinating to see but a bit frustrating that we get very little out of the visual information.
What does the result mean for us in MeMAD? Not much really, just that we can succeed in the practical rather well in some tasks we are facing with a well developed domain-specific translation engine. But the situation will be different with automatically generated audio descriptions and the integration of other modalities such as sound and speech. And speech translation was the other task we focused on in connection with the shared task of English-audio to German-text translation.
Speech-to-text translation
The report on IWSLT 2018 will be quick as our decision to participate was as well. Our main goal is to develop end-to-end models that one can feed with different modalities. However, our first attempt to train such a model failed and we focused on a more traditional pipe-line approach as most of the participants.
Our pipeline consists of a conventional ASR system, which converts English speech into text. The ASR output text is then translated into German using an NMT system. The ASR model was trained on the TED-LIUM corpus (Rousseau et al., 2014). We use the Kaldi toolkit (Povey et al., 2011) and a standard recipe that trains a TDNN acoustic model using the lattice-free maximum mutual information criterion (Povey et al., 2016). The NMT model was trained on actual ASR decoding hypotheses for the TED talks to better reflect the input we will receive during testing with the full pipeline. To be able to include more data we also created a system that produces ASR-like data from movie subtitles for which we have text-based translations. Besides of some normalisation this model actually learns to spell-out numbers and dates and produces some ASR-like noise. Some anecdotal examples are shown below.
Original English: I’m a child of 1984,
ASR-like English: i am a child of nineteen eighty four
Original English: Because in the summer of 2006, the E.U. Commission tabled a directive.
ASR-like English: because in the summer of two thousand and six you commission tabled a directive
Original English: Stasi was the secret police in East Germany.
ASR-like English: stars he was the secret police in east germany
Especially, the last example is rather entertaining and our system performed quite well on development data but somehow dropped on the official test set in performance.
Besides traditional pipeline modes, IWSLT also encouraged end-to-end models but only a few participants succeeded in submitting such a system. The difficulty of multimodal models can be seen in the results of the evaluation campaign. All those systems are far behind the pipeline systems and we are in a good company of teams that try to make it work in the future. Our efforts in year two will focus on the development of such end-to-end models making efficient use of different data sets in proper multi-task training setups. Wish us luck and stay tuned!