
End-to-end named entity recognition for spoken Finnish
Named entity recognition (NER) is a natural language processing task in which the system tries to find named entities and classify them in predefined categories, such as person, location, organization, date and product. NER is an integral part of other large natural language processing tasks, such as information retrieval, text summarization, machine translation, and question answering. The standard way of NER from speech involves a pipeline of two systems. First, an automatic speech recognition (ASR) system transcribes the speech and generates the transcripts, after which a NER system annotates the transcripts with the named entities. In the proposed end-to-end way, a single system generates both the speech transcripts and the NER annotations.
NER is a difficult task due to the lack of annotated data for certain languages or domains, such as biology and chemistry. Named entity ambiguity is another challenging aspect, for example, a word can represent a person, organization, product, or any other category, depending on the context it appears in.
Recognizing named entities from speech
In addition to ASR (automatic speech recognition) errors, spoken data imposes additional challenges to the NER system. To recognize the current named entity, the system relies on the neighboring words for the context. Spoken communication is often less formal than the typical text data that is used for training NER systems, so the neighboring words differ. Named entities are also often capitalized in text and the system trained with capitalized text data learns to rely on capitalization in order to detect the entities, which is neglected in the ASR output. Since the ASR system is not perfect and makes errors, those errors are propagated to the NER system, which is hard to recover from. Having two separate systems also means that the ASR system is not optimized for the NER task and vice versa.
To deal with the shortcomings of the pipeline approach, two end-to-end spoken NER approaches were developed at Aalto University as part of Dejan Porjazovski’s Master’s thesis 2020 (1). Finnish is a low-resourced language in the sense that there is no spoken training data that has both correct transcriptions and NER annotation. Thus, we selected the largest transcribed spoken training data, the Finnish parliament sessions (2), and used our Finnish named entity recognition system (3) to predict the named entity tags.
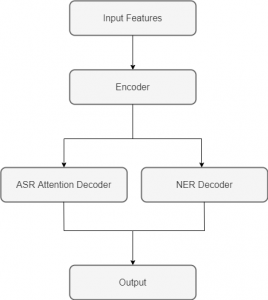
Both proposed end-to-end approaches use an attention-based encoder-decoder architecture, similar to the Listen, Attend and Spell architecture (4). The first approach is called an augmented labels approach, where the original transcripts are augmented with named entity tags. In other words, each word in the transcript is followed by its named entity tag. That way, the system learns to produce transcripts augmented with named entities. The second approach is called a multi-task approach, where there are two decoder branches. One branch is responsible for producing the automatic speech recognition transcripts and the other one for producing the named entity tags. The encoder, which processes the audio features, is shared between the branches. An illustration of the multi-task approach is shown in the figure below.
Both our proposed approaches are capable of recognizing the following named entities: ‘PER’ (person), ‘LOC’ (location) and ‘ORG’ (organization). A special token ‘O’ is reserved for all the other words that don’t belong to one of the mentioned named entity classes.
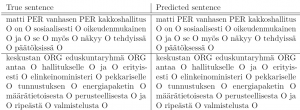
Sample automatic NER annotations for sentences produced by the augmented labels approach can be seen in the figure below.
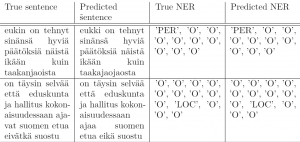
In the next figure, we can see some sample NER annotations produced by the multi-task approach.
The thorough experiments that we did, showed that the augmented labels approach is slightly better at transcribing the speech, whereas the multi-task approach achieves better results on annotating the transcripts with named entities. Nevertheless, both approaches do a good job of recognizing named entities, without sacrificing too much of the ASR performance.
References and further reading
- Porjazovski Dejan. MSc thesis: “End-to-end named entity recognition for spoken Finnish.” Master’s thesis, Aalto University, 2020.
- Mansikkaniemi, André, Peter Smit, and Mikko Kurimo. “Automatic Construction of the Finnish Parliament Speech Corpus.” INTERSPEECH. Vol. 8. 2017.
- Porjazovski, Dejan, Juho Leinonen, and Mikko Kurimo. “Named entity recognition for spoken Finnish.” Proceedings of the 2nd International Workshop on AI for Smart TV Content Production, Access and Delivery. 2020.
- Chan, William, et al. “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition.” 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.